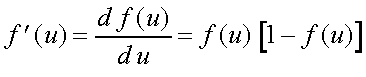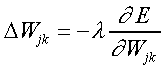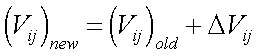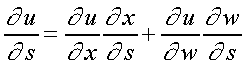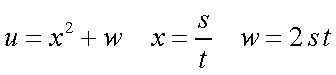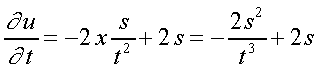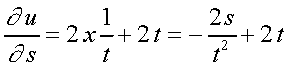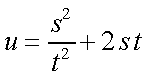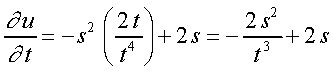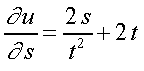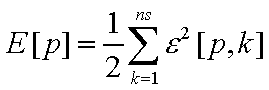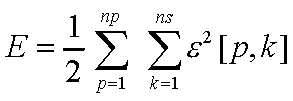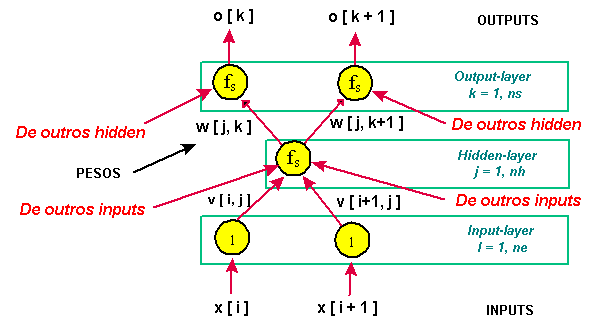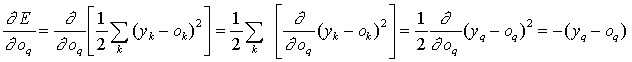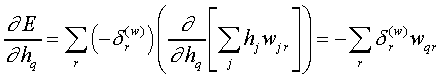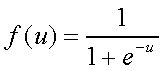
O algorítmo básico (1) para a otimização de redes neurais artificiais (ANN), e portanto para a determinação dos pesos das ligações (weights), é a seguir demonstrado. Antes, entretanto, alguns lemas e definições serão apresentados (2).
Chama-se Função Sigmóide (3):
Um resultado interessante que dai decorre é que:
Esta função, juntamente com a tangente hiperbólica, é
muito utilizada para modelar a sinapse dos neurônios, pois ambas produzem uma histerese.
A propriedade da derivada da sigmóide, que pode ser expressa em termos da própria
sigmóide apenas, simplifica bastante os cálculos computacionais.
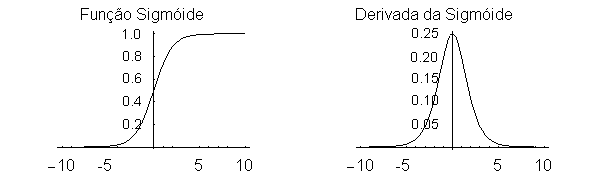
Figura 1: A Função Sigmóide
Dado as funções Vij (peso associado aos neurônios da input-layer i e da hidden-layer j ), Wjk (peso associado aos neurônios da hidden-layer j e da output-layer k) e uma função objetivo E (V,W) a ser minimizada (erro da previsão efetuada pela rede neural com os pesos V e W), o valor ótimo (local ou global, não se sabe) de V e W é obtido através dos passos a seguir, onde é um parâmetro que regula a velocidade da convergência (chamado de taxa de aprendizagem ou learning rate):
(1)
Note-se que Delta é proporcional ao gradiente de E.
Dadas três funcões u = u [ x ( s, t ) , w ( s, t ) ] então:
(2)
Exemplo:
Então, pela chain-rule:
Agora, pela derivação direta, chegamos ao mesmo resultado:
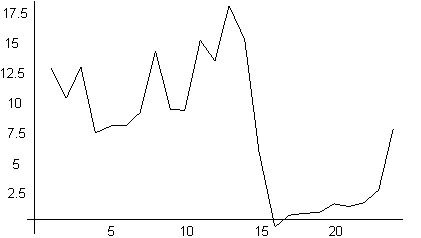
Figura 2: Taxa Mensal de Inflação medida pelo IGP-DI para 1985-86 (24 meses)
Suponhamos que uma rede deva ser treinada para apreender os dados acima e depois prever o que ocorrerá a partir de 1988. Construindo uma rede com 6 entradas e uma saída, definimos então os vetores:
X [ p ] = { x [ p, i ] } = { 12.64, 10.10, 12.70, 7.23, 7.79, 7.82 } e
Y [ p ] = { y [ p, k ] } = { 8.93 }
como sendo os vetores de entrada (jan-jun/85) e saída (jul/85) para o pattern (ou época) p = 1. Com uma dada configuração de pesos { V, W } e para uma entrada X [ p ], a rede irá produzir uma saída:
O [ p ] = { o [ p, k ] } = { 8.75 } ( 8.75 é exemplificativo)
O erro e [ p, k ] cometido pelos neurônios de saída no pattern p terá sido de:
e [ p, k ] = y [ p, k ] - o [ p, k ] = { 0.18 }
Definem-se o erro E [ p ] do pattern p e o erro total da rede E por:
onde
ns = nº de neurônios de saída
ne = nº de neurônios de entrada
nh = nº de neurônios na hidden-layer
np = nº de patterns
Figura 3: Trecho de uma rede neural
Para o cálculo dos pesos usaremos o conhecido algorítmo do steepest-descent (descida mais íngreme). Precisamos calcular as derivadas parciais do erro E com relação aos pesos W e V (Eq. 1.2 e 1.3). Para tanto, definamos a soma R [ j ] dos sinais que chegam a cada hidden-neuron, o sinal de saída h [ j ] de cada hidden-neuron (obtido pela ação de uma sinapse f sobre R), a soma S [ k ] dos sinais que chegam ao output-neuron e o sinal de saída o [ k ] do output-neuron (também obtido pela ação de uma sinapse f sobre S) (Fig. 3):
(3)
Essas relações definem completamente o sistema e constituem o modelo matemático da rede neural (simplificada) do cérebro humano.
Vamos agora deduzir a Delta-Rule. Para abreviar a notação, usaremos E em lugar de E [ p ], pois estamos supondo que o treinamento seja feito otimizando-se os pesos para a apresentação de cada pattern, quando então E [ p ] se mantém constante. Existem também outros esquemas de treinamento, que não alteram a dedução abaixo. No entanto, ainda não foi demonstrado que a soma dos E [ p ] mínimos é igual ao mínimo de E.
Definição do Delta (4)
Pela Chain-Rule
De (1) e (3)
(5)
Definição de Delta (6)
Pela Chain-Rule
De (1) e (3)
Pela Chain-Rule generalizada
(7)
De (1) (2) (3) (4)
De (1) (2) (3) (6)
Expressão do steepest-descent (8)
Expressão do steepest-descent (9)
USO DO ALGORÍTMO
O treinamento da rede se dá pelos seguintes passos:
1. Randomizam-se os pesos W e V da rede.
2. Injeta-se um pattern X nos neurônios de entrada.
3. Calculam-se por (5) os deltas dos w's, usando-se a saída esperada Y.
4. Calculam-se por (7) os deltas dos v's; note-se que aqui os deltas das saídas são repropagados nos hidden-neurons, dado pela somatória em (7), donde o nome de back-propagation algorithm.
5. Calculam-se os novos pesos W e V por (8) (9) e (1).
6. Volta-se a 2, desde que o erro E [ p ] tenha diminuído mais que um certo limite.
A convergência desse algorítmo, num caso real, pode levar horas, donde a necessidade de sua programação ser feita em linguagem rápida (como C ou Assembly), e CPU bastante rápida (processamento paralelo, por exemplo).
Notas:
(1) Ver [Kosko, p.207], [Rumelhart, vol.1, p.322], [Masters, p.94], [Freeman, p.72], [Blum, p.55]. A notação é bastante confusa nesses autores. Aqui traduzimos para uma notação inteligível.
(2) Os gráficos e cálculos foram feitos com Mathematica 3.0. As equações foram editadas com o Editor Matemático do MS Word 97.
(3) "Sigmóide" vem
do grego ![]() = letra sigma, mais o sufixo
= letra sigma, mais o sufixo ![]() = parecido com.
= parecido com.